Machine Learning – не только нейронки
Нейронные сети и глубокое обучение (deep learning) у всех на слуху, но нейросети – это лишь подобласть такого обширного предмета, как машинное обучение (machine learning). Существует несколько сотен других алгоритмов, которые способны быстро и эффективно решать задачи искусственного интеллекта и в большинстве случаев являются более интерпретируемыми для человека. В этой статье рассмотрим алгоритмы классического машинного обучения, принцип работы нейросетей, подготовку данных для обучения моделей и задачи, которые решают с помощью искусственного интеллекта (ИИ).
Основные задачи машинного обучения
-
Восстановление регрессии (прогнозирования) – построение модели, способной предсказывать численную величину на основе набора признаков объекта.
-
Классификация – определение категории объекта на основе его признаков.
-
Кластеризация – распределение объектов.
Допустим, есть набор данных со статистикой по приложениям. В нем есть следующие сведения: размер, категория, количество скачиваний, количество отзывов, рейтинг, возрастной рейтинг, жанр и цена. С помощью этого набора данных и машинного обучения можно решить такие задачи:
-
Прогнозирование рейтинга приложения на основе признаков: размер, категория, возрастной рейтинг, жанр и цена – задача регрессии.
-
Определение категории приложения на основе набора признаков: размер, возрастной рейтинг, жанр и цена – задача классификации.
-
Разбиение приложений на группы на основании множества признаков (например, количество отзывов, скачиваний, рейтинга) таким образом, чтобы приложения внутри группы были более похожи друг на друга, чем приложения разных групп.
Нейронные сети (многослойный перцептрон)
Существует мнение, что лучшие идеи для изобретений человек заимствует у природы. Нейронные сети – это именно тот случай, ведь сама концепция нейросетей базируется на функциональных особенностях головного мозга.
Принцип работы
Есть определенное количество нейронов, которые между собой связаны и взаимодействуют друг с другом путем передачи сигналов. Также есть рецепторы, которые получают информацию, поступающую извне, и исполнительный орган, на который приходит итоговый сигнал. По схожему принципу работают искусственные нейросети: есть несколько слоев с нейронами и связи между ними (каждая связь имеет свой весовой коэффициент). По связям передаются сигналы в виде численных значений, первый слой выполняет собой роль рецепторов, то есть получает набор признаков для обучения, и есть выходной слой, который выдает ответ.
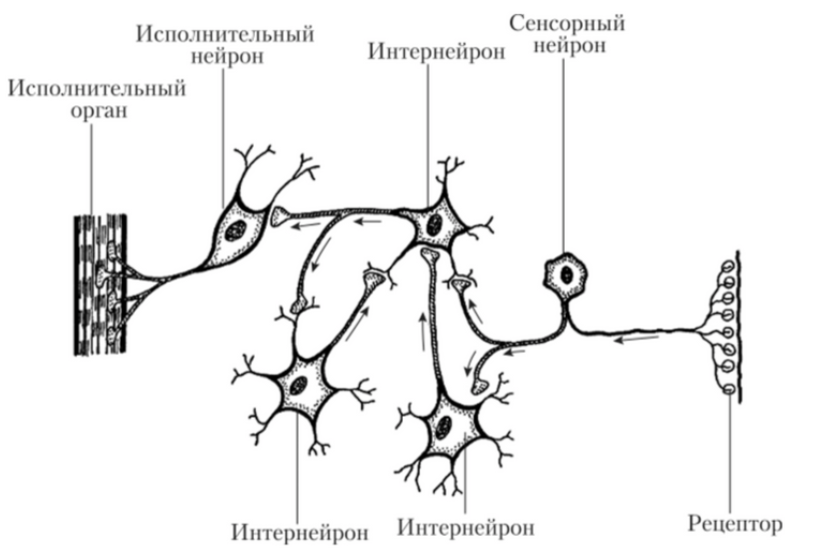
Нейронные связи в головном мозге («Создаем нейронную сеть», Тарик Рашид)
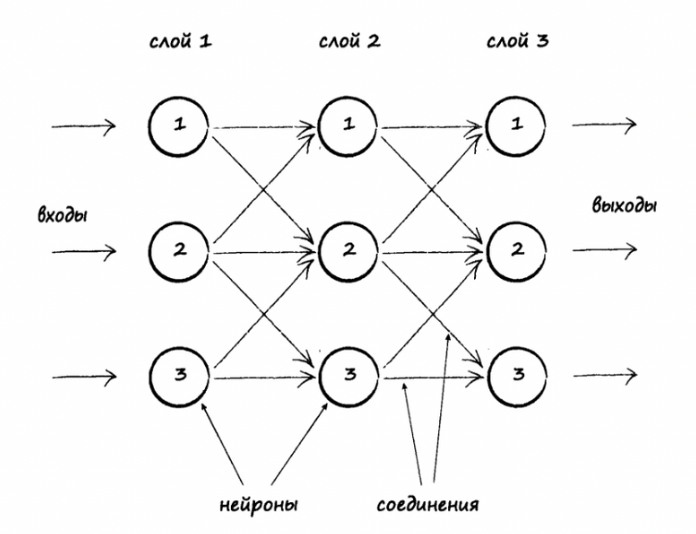
Пример искусственной трехслойной нейросети («Создаем нейронную сеть», Тарик Рашид)
Каждый слой нейросети оперирует разными представлениями о данных. На рисунке ниже можно увидеть пример использованиям глубокого обучения (нейросети) для распознавания образа на картинке. На входной слой нам поступают пиксели изображений, далее после вычислений между входным и первым скрытым слоем мы получаем границы, на втором скрытом слое – контуры, на третьем – части объектов, на выходном – вероятности принадлежности изображения к каждому типу объектов.

Пример использования нейросети для распознавания образа ( «Глубокое обучение», Ян Гудфеллоу)
Как настраивать
Настраивается путем задания количества узлов, скрытых слоев и выбора функции активации. В искусственных нейронных сетях функция активации нейрона отвечает за выходной сигнал, который определяется входным сигналом или набором входных сигналов.
Какие задачи решают
Нейросети применяют для решения задач классификации, регрессии и кластеризации.
Классические алгоритмы машинного обучения (Machine Learning)
K-ближайших соседей
Метод K-ближайших соседей – простой и эффективный алгоритм, его можно описать известной поговоркой: «Скажи мне, кто твой друг, и я скажу, кто ты».
Принцип работы
Пусть имеется набор данных с заданными классами. Мы можем определить класс неизвестного объекта, если рассмотрим определенное количество ближайших объектов (k) и присвоим тот класс, который имеет большинство «соседей». Посмотрим на рисунок ниже.
Есть набор точек с двумя классами: синие крестики и красные кружки. Мы хотим определить, к какому классу относится неизвестная зеленая точка. Для этого мы берем k ближайших соседей, в данном случае 3, и смотрим, к каким классам они относятся. Из трех ближайших соседей больше оказалось синих крестиков, соответственно, мы можем предположить, что зеленая точка также, скорее всего, относится к этому классу.

Как настраивать
Необходимо подобрать параметр k (количество ближайших соседей) и метрику для измерения расстояний между объектами.
Какие задачи решает
В основном – классификация, но может применяться и для задач регрессии.
Линейная регрессия
Линейная регрессия – простая и эффективная модель машинного обучения, способная решать задачи быстро и недорого.
Принцип работы
Модель линейной регрессии можно описать уравнением y =a0 + a1x1 + a2x2+...+anxn, где x – это значения признаков, y – целевая переменная, a – весовые коэффициенты признаков. При обучении модели весовые коэффициенты подбираются таким образом, чтобы как можно лучше описывалась линейная зависимость признаков от целевой переменной.
Пример: задача предсказания стоимости квартиры в зависимости от площади и удаленности от метро в минутах. Целевой переменной (y) будет являться стоимость, а признаками (x) – площадь и удаленность.
На рисунке ниже также представлен пример построения линейной регрессии. Красная прямая более точно описывает линейную зависимость x от y.

Как настраивать
Для многих моделей Machine Learning, в частности и для линейной регрессии, можно улучшить итоговое качество с помощью регуляризации.
Регуляризация в статистике, машинном обучении, теории обратных задач — метод добавления некоторых дополнительных ограничений к условию с целью решить некорректно поставленную задачу или предотвратить переобучение, то есть ситуацию, когда модель хорошо показывает себя на тренировочный данных, но перестаёт работать на новых.
Распространенные методы регуляризации для повышения качества модели линейной регрессии:
-
Ridge — один из методов понижения размерности. Применяется для борьбы с переизбыточностью данных, когда независимые переменные коррелируют друг с другом (мультиколлинеарность), вследствие чего проявляется неустойчивость оценок коэффициентов линейной регрессии.
-
LASSO — также как и Ridge, применяется для борьбы с переизбыточностью данных.
-
Elastic-Net — модель регрессии с двумя регуляризаторами L1, L2. Частными случаями являются модели LASSO L1 = 0 и Ridge регрессии L2 = 0.
Какие задачи решает
Задача регрессии.
Логистическая регрессия
Логистическая регрессия – также простая и эффективная модель машинного обучения, способная решать задачи быстро и недорого.
Принцип работы
Алгоритм логистической регрессии очень похож на алгоритм линейной регрессии. Несмотря на свое название, решает задачу бинарной классификации (классы: 1 и -1). Сумма a1x1 + a2x2+...+anxn проходит через функцию сигмоиды, которая возвращает число от 0 до 1, характеризующее вероятность отнесения объекта к классу 1. Пример: логистическую регрессию часто применяют в задачах кредитного скоринга, когда по определенным данным о клиенте нужно определить, стоит ли выдавать ему кредит.

Иллюстрация алгоритмов линейной и логистической регрессии
Как настраивать
Как и в случае с линейной регрессией, существуют реализации с коэффициентом регуляризации можно выбрать один из методов регуляризации: Ridge, LASSO, Elastic-Net.
Какие задачи решает
Задача классификации.
Метод опорных векторов (SVM)
Принцип работы
Чтобы лучше всего понять алгоритм метода опорных векторов, рассмотрим рисунок. На рисунке приведен пример двух линейно разделимых классов в двумерном пространстве. Идея алгоритма заключается в нахождении оптимальной разделяющей прямой (или гиперплоскости для более высоких пространств) для отделения объектов одного класса от другого. Пунктирные линии выделяют разделяющую полосу и проводятся через объекты, которые называют опорными. Чем шире разделяющая полоса, тем качественнее модель SVM. Чтобы определить класс объекта, достаточно определить, с какой стороны гиперплоскости он находится.

Как настраивать
Необходимо подобрать оптимальное ядро (функцию переводящую признаковое пространство в более высокую размерность), если линейная зависимость слабо выражена.
Какие задачи решает
Применяется для решения задач классификации и регрессии.
Сравнение классических алгоритмов с нейросетью
Для примера был взят датасет со статистикой приложений в Play Market. Датасет содержит следующие данные: размер приложения, возрастной рейтинг, количество скачиваний, жанр, категория и др. На данном датасете были обучены модели: линейная регрессия, метод опорных векторов, нейронная сеть (многослойный перцептрон).
В ходе экспериментов были подобраны следующие параметры для моделей машинного обучения:
-
Линейная регрессия – модели линейной регрессии с регуляризацией не показали результат, превосходящий качество классической линейной регрессии.
-
Метод опорных векторов – модель метода опорных векторов с RBF-ядром показала лучший результат по сравнению с другими ядрами.
-
Многослойный перцептрон – оптимальный результат показала модель с 4 слоями, 300 нейронами и функций активацией ReLu. При попытках увеличить количество слоев и нейронов прирост качества не наблюдался.
Была решена задача прогнозирования потенциального рейтинга приложения в зависимости от его признаков.
Результаты ошибки среднего отклонения от истинного значения целевой переменной в процентах для каждой модели:
-
Линейная регрессия – 6.13 %
-
Метод опорных векторов – 6.01%
-
Нейронная сеть – 6.41%
Таким образом, классические алгоритмы машинного обучения и нейросети показали приблизительно одинаковое качество. Это связано с тем, что нейросети хорошо обучаются на датасетах с большим размером и обычно применяются для решения задач, где зависимость в данных очень сложна. Поэтому для решения данной задачи можно обойтись применением классических алгоритмов и не прибегать к использованию нейросетей.
На гистограмме ниже представлены итоговые весовые коэффициенты a, полученные при обучении модели линейной регрессии. Чем больше столбик, тем выше влияние признака на целевую переменную. Если столбик направлен вверх, то он оказывает положительное влияние на рост целевой переменной, если вниз – то отрицательное. Другими словами, если приложение имеет жанр “Other” или “Tools”, то, скорее всего, его рейтинг будет высоким, а если у него категория “FAMILY” или “GAME” – то, вероятно, низким. Данная интерпретация весовых коэффициентов линейной регрессии бывает очень полезной при анализе данных.

Гистограмма значений коэффициентов линейной регрессии
Примеры из нашей практики
Искусственный интеллект и машинное обучение используют для решения бизнес-задач в ритейле, медицине, промышленности и иных отраслях. Мы в своей практике тоже работаем над системами распознавания, компьютерного зрения, предиктивной аналитики. Например, в одном из проектов мы реализовали классификатор, который по фотографии тестера пользователя помогал в диагностике ряда заболеваний.
Познакомьтесь с нашими решениями Machine Learning и другими кейсами в портфолио.