О чем подумать перед запуском: первые шаги по нагрузке продукта
Во времена dial-up модемов мы ждали минуты, когда загрузится одна страница сайта, и считали это нормой. Сейчас ситуация изменилась - мы не готовы ждать даже 10 секунд. Однажды увидев ошибку на странице, мы найдем аналогичный ресурс, который работает без сбоев, а к предыдущему уже вряд ли вернемся.
Если вы не можете однозначно ответить на вопросы:
- Справится ли приложение с планируемым потоком пользователей?
- Будет ли оно работать, если количество пользователей увеличится?
- Какое количество пользователей способны выдержать сервера?
- Что произойдет, если нагрузка станет больше, чем способны выдержать сервера?
- Смогут ли сервера восстановить свою работу и за какое время, если количество посетителей приведет к сбою системы?
- Будет ли сервис работать также стабильно через неделю, месяц, год?
Самое время задуматься о нагрузочном тестировании вашей системы или сервиса.
Чего ждут пользователи
Мгновенной работы без сбоев и ошибок. По данным исследования компании Akamai:
- 47% пользователей ожидают, что веб-страница загрузится в течение 2 секунд;
- 40% посетителей уходят с сайта, который грузится более 3 секунд;
- 52% утверждают, что быстрая загрузка повышает их лояльность.
Медленная загрузка сайта подрывает лояльность пользователей к компании. Это подтверждает исследование компании Gomez:
- в часы пик 75% посетителей ушли на сайты конкурентов, не дождавшись загрузки страницы;
- 88% посетителей вряд ли вернется на сайт после неудачной попытки его открыть;
- 55% пользователей выразили менее позитивное мнение о компании в целом, если сайт медленно открывался;
- 33% поделились негативным впечатлением со знакомыми.
Так что, если проблемы с нагрузкой появились, бизнес уже несет убытки: падает количество пользователей, меньше заказов, больше недовольных отзывов. Правильно рассчитать нагрузку на сервис и «железо» нужно заранее, еще до запуска проекта.
Нагрузка. Первые шаги
Итак, вы решили, что нагрузочное тестирование необходимо. Ниже мы приведем основные шаги, которые помогут позаботиться о нагрузке заранее.
Подготовка
Думать о нагрузке нужно на этапе подготовки архитектуры будущего сервиса, а проводить - после функциональных тестов, когда исправлены все недочеты функционала.
Шаг 1. Цели и требования
Формулируем их до начала работ. От этого будет зависеть, каким образом мы будем нагружать систему и какие показатели будем смотреть. Для разных целей анализ будет разным.
Цели, например, могут быть такие:
- Определить максимальную производительность системы на существующей конфигурации;
- Проверить надежность системы: анализируем возможные утечки памяти и влияние сторонних регулярных задач на работу системы. Например, когда создается резервная копия базы данных;
- Выявить потенциально «узкие» места системы.
Основные требования обычно такие:
Время обслуживания: 90% запросов должны обслуживаться в пределах 10 секунд. Требовать обслужить вовремя все 100% запросов бессмысленно - 10% это резерв для внештатных ситуаций и статистических выбросов. Для разных запросов требования времени обслуживания могут отличаться: для перехода на внутреннюю страницу нужны доли секунд, а для загрузки годового отчета - несколько минут;
Ёмкость: система должна обслуживать 100 одновременных пользователей и оставаться в рамках пункта 1.
В общих случаях, для начала тестирования такой формулировки требований достаточно. Если же система использует нестандартные протоколы или функционал: видео, стриминг, требования будут формулироваться индивидуально.
Шаг 2. Пользовательские сценарии
Следующим шагом воссоздаем работу реальных пользователей с системой. Для этого нужны пользовательские сценарии, на основе которых будем нагружать систему.
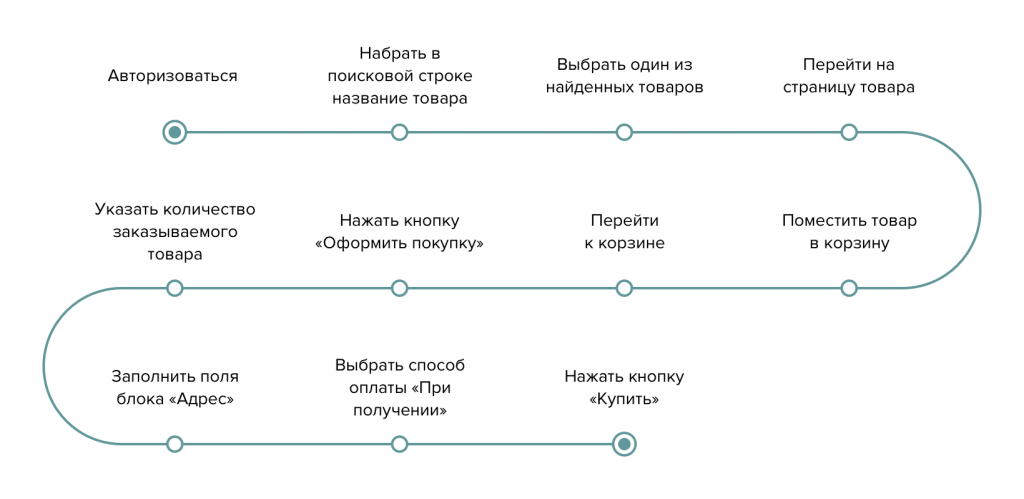
При подготовке сценариев нагрузочного тестирования не нужно покрывать всю существующую функциональность, поэтому выделяем самые важные и часто используемые действия пользователей: поиск, выбор и покупка, оплата, оформление заказа. Не берем в расчет, например, смену пароля, изменение аватарки или паспортных данных - это тот функционал, который не отразится на общей оценке работоспособности системы. Это сэкономит время на разработке скриптов.
Шаг 3. Инструменты тестирования
Основной инструмент нагрузочного тестирования, который мы используем - Jmeter. Это не единственный инструмент, но наиболее популярный. Он подходит для большинства проектов благодаря гибкости, кроссплатформенности и поддержке большого числа протоколов. К тому же, Jmeter - бесплатный инструмент, который поддерживается большим сообществом разработчиков: они сами улучшают готовое решение, которым можно воспользоваться бесплатно.
Для Jmeter разрабатываем скрипты: набор команд, отправляемых на сервер при активности пользователя. Каждый скрипт имитирует отдельное действие пользователя: вход, ввод логина/пароля, поиск, добавление товаров в корзину и т.д. Вместе они образуют пользовательский сценарий из шага 2. Чтобы проверить, сколько пользователей выдержит система, используем несколько виртуальных пользователей в группе (их количество зависит от целей и требований из шага 1).
Шаг 4. Тестовые данные и скрипты
Возьмем нагрузку интернет-магазина. Чтобы ее проверить, нам нужны достаточное количество уникальных пользователей, документов или товаров.
Допустим, предполагаемое количество клиентов - 1000 человек. В этом случае проверяем, как будет работать система, если все 1000 человек будут заказывать товары одновременно. Значит, создаем 1000 пользователей. Если в будущем число пользователей увеличится, создаем больше пользователей заранее, чтобы узнать предел посетителей, который система способна выдержать.
- все скрипты были отлажены;
- тестовые данные подготовлены;
- согласована нагрузка, которая будет подаваться на систему и на серверах;
- установлены агенты, которые будут следить за метриками: расходом памяти, процессорного времени, файла подкачки и сетевой активностью.
Перед непосредственным тестированием проверяем, чтобы:
Шаг 5. Непосредственно нагрузка
Строим профиль нагрузки исходя из цели. Например, для определения емкости системы конфигурируем тест так, чтобы число работающих пользователей росло. Мониторим сервера, время ответа и долю ошибок, замечаем когда происходит первая точка перегиба - насыщение теста. Это точка начала деградации: вроде бы нагрузка еще держимся в пределах требований, но предел ресурсов машины уже близко.
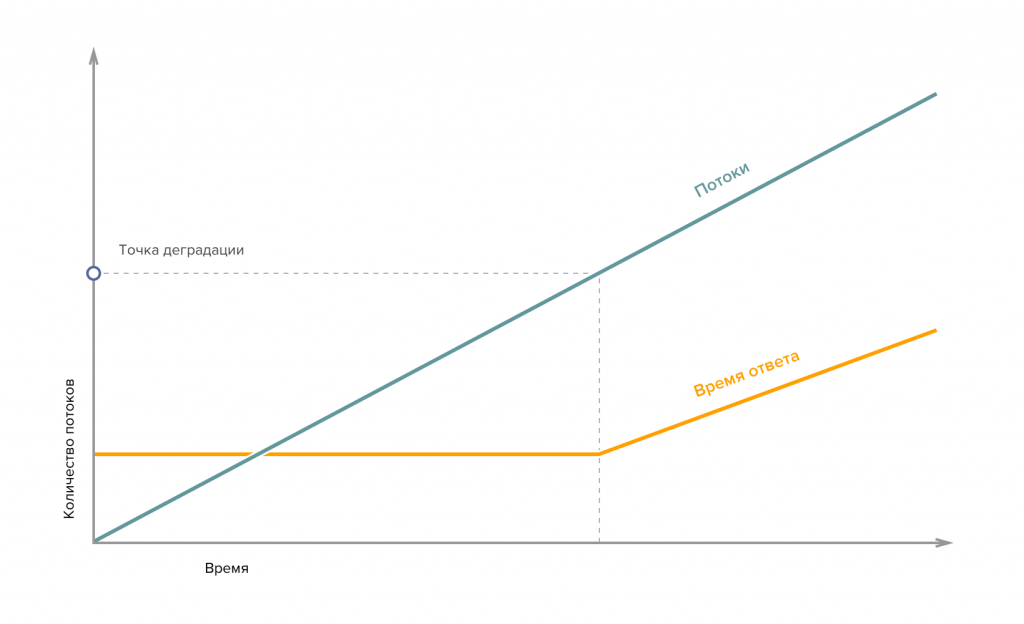
Следующая точка нарушения требований - мы уходим за пределы нормального обслуживания. Система работает, но это наш предел нормального обслуживания.
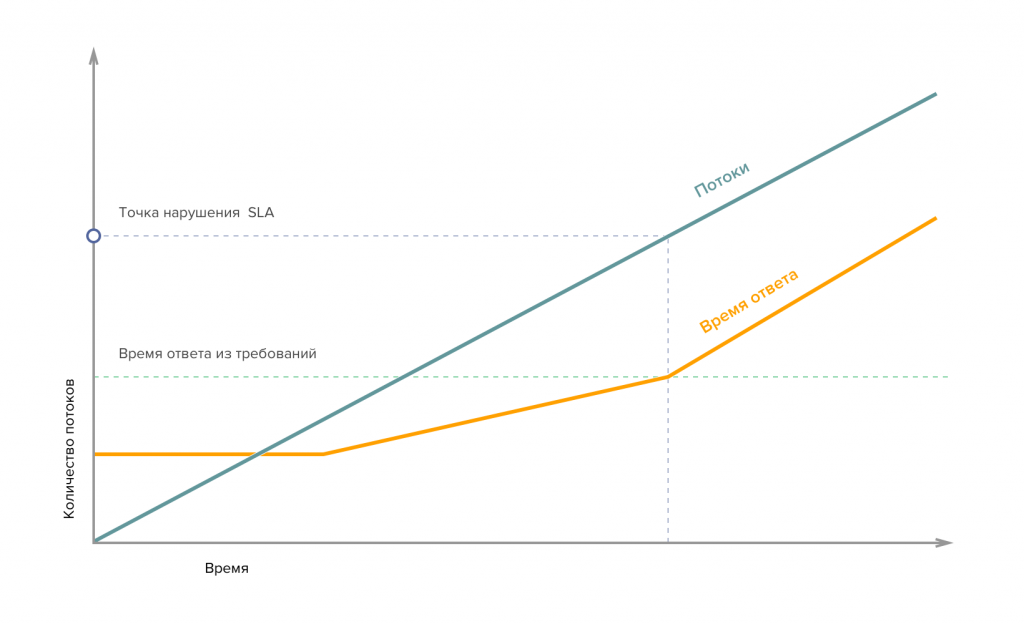
Система на пределе нормального обслуживания
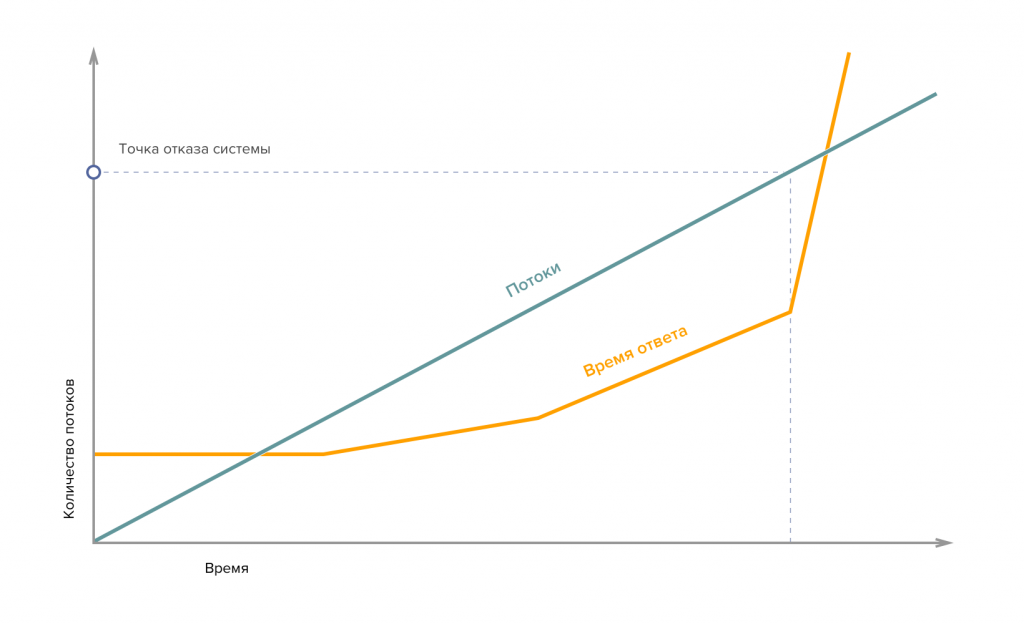
Мы идем дальше и пытаемся работать дальше, как получится. Следующий шаг - точка отказа: память или процессорное время заканчивается, и сервис «замолкает». Тут останавливаем тест и фиксируем предельную емкость системы.
Шаг 6. Анализ результатов
Анализируем данные, полученные в ходе тестирования: метрики, логи приложения, данные об утилизации ресурсов каждого из серверов системы, логи базы данных и выявляем проблемные и «узкие» места. Проблемы могут оказаться разнообразными: от неверной настройки какого-то сервера, входящего в систему, до взаимных блокировок процессов в базе данных или ошибки в коде приложения. Часто подобные проблемы невозможно выявить на этапе функционального тестирования, когда системой пользуется 2-3 человека. Без нагрузочного тестирования проблема обнаружится на этапе эксплуатации, когда приложением начнут пользоваться сотни и тысячи посетителей.
Что касается «узких» мест системы или архитектуры, то скорость системы – это скорость самого медленного ее компонента. Предположим, что система состоит из нескольких микросервисов. У каждого есть собственное время отклика и устойчивость к нагрузке. Добавим сюда тип базы данных, сервера и конфигурацию оборудования. Пользователям приложения нужен быстрый отклик системы и ее доступность. В процессе анализа нагрузочных тестов выявляем узкие места в архитектуре и независимо масштабируем и настраиваем микросервисы, чтобы добиться быстрого отклика системы целиком. Обнаружение одного из таких узких мест, или «бутылочных горлышек», видно на графике зависимости утилизации процессорных мощностей одного из серверов системы от количества пользователей, одновременно работающих с системой. Когда количество посетителей превысило 200 пользователей, загрузка процессора данного сервера достигла 100%, и весь сервис переставал отвечать. К слову, нагрузка была меньше, чем предполагаемое количество реальных пользователей.

Как только на сервере модернизировали процессор, количество одновременных пользователей выросло в 2,5 раза. Это превышало планируемую нагрузку на сервис.
После нагрузочного тестирования составляется отчет о результатах тестирования. Он включает список ошибок, предложения по оптимизации работы системы и общие рекомендации.
Итоги
Многие пренебрегают проверкой нагрузки, надеясь, что до проблем не дойдет. Как говорится, доверяй, но проверяй. Проверка нагрузки перед запуском сервиса убережет продукт от медленной и некорректной работы, определит предел его работоспособности именно на выбранном оборудовании. Практика показывает, что простых корректировок конфигурации достаточно, чтобы ускорить проект в 5-10 раз и сделать его устойчивым к стрессовым нагрузкам.